 Figure 2 - Visible record structure
Figure 2 - Visible record structure
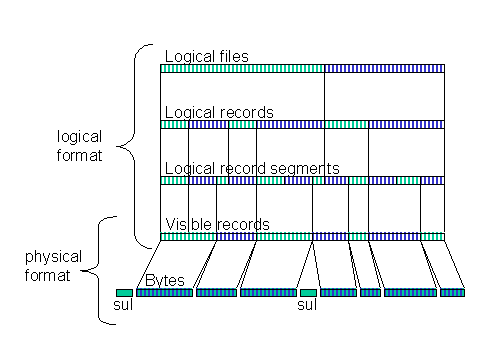
Figure 1 shows the transition from media-dependent organization of data (the physical format) to media-independent organization of data (the logical format). Notice that the two overlap at the visible record layer. Viewed from "above", the visible record layer is just a record-oriented organization of a stream of bytes, which looks the same to higher layers regardless of the medium used to record the bytes. Viewed from "below", the visible record layer is a mechanism that supports mapping logical constructs onto physical constructs such as device blocks and multiple storage units (e.g., tapes or disk files).A value, whether in a logical record or a visible record header or trailer, is encoded in one or more contiguous bytes according to one of a variety of standard representations. Each standard representation is identified by a unique integer code, called a representation code.Logical record segmentation supports the flexible mapping of logical records (which may be of highly-varying sizes) into visible records. In particular, segments make it possible to begin a new logical record in the middle of a visible record. This results in two benefits. One, fixed-length visible records may be used. This provides a powerful recovery method in case corrupted data is encountered and also allows implementation of random access methods. Two, segmentation allows efficient packing of logical records into larger device blocks while also allowing spanning of large logical records across smaller device blocks.
An encoding representation may be simple or compound. A simple representation is an encoding of a single atomic value such as an integer, decimal number, or character string. A compound representation is an encoding that is built up of previously-defined encodings and represents two or more simple values organized into a useful structure. The length of every representation is either fixed or may be determined from its content.
A subfield of a representation is any part of the representation
that corresponds to a simple encoding
(with an exception for representation code DTIME).
Each subfield of a representation has a subfield name
and subfield position, described in Table 13.
Representation codes IDENT and ASCII include USHORT and UVARI values,
respectively, to count number of characters in a string.
However, there is no simple representation code corresponding
to only the characters.
Consequently, IDENT and ASCII are considered to be
simple representations rather than compound.
Representation code DTIME uses 4-bit fields to represent time zone and
month.
The representation codes specified in Table 12 are
divided into representation code classes.
The codes in a representation code class are
capable of representing the same kinds of values.
Codes within a class are typically differentiated by
amount of range or precision or alignment to
a particular computing architecture.
This organization of codes into classes is used
when defining attributes for a schema (see Part 1).
A representation code restriction may be specified for the
attribute to indicate its possible range and precision,
but any other code in the
class may be used that suppports the value being recorded.
For example, the codes UNORM (normal unsigned integer) and FDOUBL
(double precision floating point) are in the same large class,
since each is capable of representing a number.
FDOUBLE has more range and precision than UNORM.
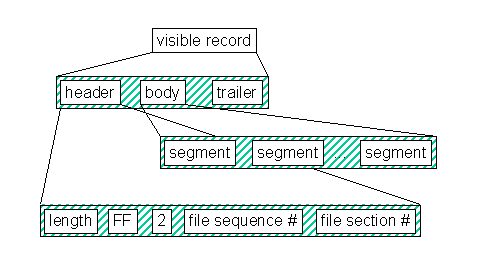
Visible records are the interface between the logical format and a medium-specific physical format. They provide a structure that can be mapped into device structures and into which logical record segments may be packed.
A visible record is composed of three disjoint parts in the following order:
The parts of a visible record are described in detail in 6.2 to 6.4.
Figure 2 - Visible record structure
The visible record header contains information about the length of the visible record, the format version being used, and the logical file in which the segments contained in the visible record belong.
Table 1 describes the fields of a visible record header in the order in which they appear.
| Table 1 - Visible Record Header Fields | |||
| *Note | Field | Size in Bytes | Representation Code |
| 1 | Length | 4 | ULONG |
| 2 | The value FF16 | 1 | USHORT |
| 3 | Format version | 1 | USHORT |
| 4 | File sequence number | 4 | ULONG |
| 5 | File section number | 2 | UNORM |
1 This field specifies the length in bytes of the visible record, including the header, body, and trailer. The maximum length of a visible record is limited by the largest even number having representation ULONG (see Table 12). This number is 4 294 967 294. The actual maximum length used for a visible record may depend on which medium the data is recorded (see Part 3). The minimum length of a visible record is the length of its header plus trailer plus the minimum length of a logical record segment (see Table 2).
2 This field contains the hexadecimal value FF. Its purpose is twofold: (1) to make the header length even, and (2) to provide a necessary (although not sufficient) identifier of a visible record.
3 The format version field contains the major RP 66 version of the data being recorded. For this edition of the standard, the format version value is 2.
4 This is the sequence number of the logical file to which the segments contained in the visible record body belong (see Part 6). Inclusion of this field implies the following requirement: All of the logical record segments contained in a visible record must belong to the same logical file.
5
This is the section number of the logical file
to which the segments contained in
the visible record body belong (see 10.1).
By having a file sequence number in the visible record header,
it is possible to
implement rapid file access methods based on scanning
only visible record headers.
If visible records are fixed-length, for example, then an application
may compute forward or backward a given number of
visible record lengths, jump to that location and
determine by looking at the visible record header
whether the jump landed inside or outside the current logical file.
In RP 66 version 1, the visible record length was
arbitrarily limited to 16,384
even though its representation (UNORM) supported lengths up to 65,534.
This was done to ensure that implementations on
small-memory processors would
not be prevented from reading any RP 66 data.
This was found to be a burdensome limitation and one that
should be administered by the various user groups.
So, in this edition of the standard, no arbitrary length limitation is
imposed beyond what is supported by the ULONG representation.
How visible records are used for various media types and various application
purposes is described in Part 3. This includes how to specify variable-length or
fixed-length visible records, for example.
Logical records organize values into coherent, semantically-related packets of information. A logical record may have any length greater than or equal to sixteen bytes and is organized in one of two syntactic forms: explicitly-formatted logical record (EFLR), or indirectly-formatted logical record (IFLR).
The content of an EFLR is determined from an analysis of the record itself. That is, an EFLR is self-descriptive in the sense that the type of, order of, and amount of information it contains may be determined by reading the record. Further information about EFLRs is given in 8.
The content of an IFLR is determined from an analysis of related EFLRs. The
type of, order of, and amount of information in an IFLR is described by information in one
or more EFLRs. A reference within each IFLR allows a reader to locate the data items
within EFLRs that describe it. Many IFLRs may reference the same descriptor
information. Further information about IFLRs is given in 9.
The first view is static vs dynamic. Static data has a fixed or static value within
the context of a logical file and is recorded in EFLRs. Dynamic data has a
dynamically-changing value in a logical file, each instance of the value
occurring in a different IFLR. For example, the description of a sensor is static,
whereas the values acquired by the sensor over time are dynamic.
The second view is parametric vs bulk. Parametric data is complex (typically
tabular) in form and of known extent, whereas bulk data is sequential in form
and has an indefinite extent, i.e., the extent may not be known when data
recording begins. Parametric data, e.g., computation parameters, is recorded
in EFLRs, and bulk data, e.g., seismic traces, is recorded in IFLRs.
EFLRs and IFLRs are designed to handle different kinds of data, the
differences resulting from either form or purpose.
One of two views typically applies:
A logical record is implemented as one or more logical record segments.
Segments contain the structure necessary to describe and support the physical
implementation of a logical record.
A segment is contained in a single visible record and
is composed of up to four mutually-disjoint parts
in the following order:
There is a very strict relation between segments and visible records. As stated earlier, a visible record body consists exactly of a whole number of logical record segments. Segments cannot span visible records, but logical records can and frequently do. It is also common for many logical records to fit into one large visible record, in which case each logical record normally has only one segment. A logical record will typically have more than one segment only when it cannot fit completely into the current visible record. The power of segments is that they allow complete separation of logical record and visible record alignment. The only exception to this alignment independence is with the first logical record of a logical file, which is described later.Figures 3 and Figure 4 illustrate logical record segmentation.
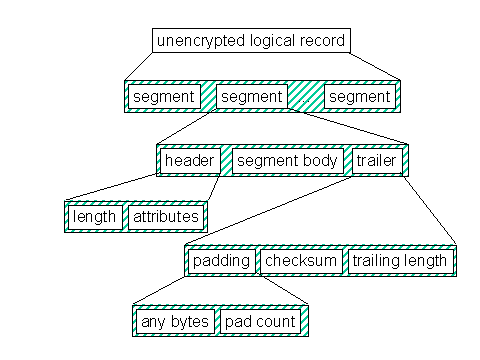 Figure 3 - Logical record segmentation (without encryption)
Figure 3 - Logical record segmentation (without encryption)
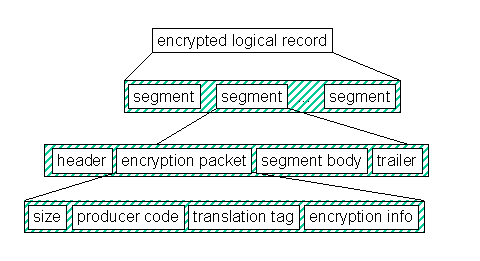 Figure 4 - Logical record segmentation (with encryption)
Figure 4 - Logical record segmentation (with encryption)
Table 2 describes the fields of a logical record segment header in the order in which they appear.
| Table 2 - Logical Record Segment Header Fields | |||
| *Note | Field | Size in Bytes | Representation Code |
| 1 | Length | 4 | ULONG |
| 2 | Attributes | 2 | (see note) |
1 This field specifies the length in bytes of the segment, including the header, encryption packet, body, and trailer. A segment is required to have an even number of at least sixteen (16) or more bytes. The maximum length of a logical record segment is limited by the largest even number having representation ULONG (see Table 12). This number is 4 294 967 294.
2
Attributes are represented by bit values in a two-byte field, where bit 8 of each
byte represents the highest-order bit and bit 1 represents the lowest-order bit (see
Table 3).
The even length ensures that two-byte checksums can be computed.
The minimum size, when combined with visible record overhead ensures a
minimim physical block size required by some devices.
Table 3 describes the meanings of the bits in the logical record segment header attributes field. A bit is said to be set if its value = 1, and clear if its value = 0.
| Table 3 - Logical Record Segment Header Attributes | ||||
| *Note | Byte:Bit | Label | Value | Description |
| 1 | 1:8 | Logical record structure | 0 | Indirectly-formatted logical record. |
| 1 | Explicitly-formatted logical record. | |||
| 2 | 1:7 | Predecessor | 0 | This is the first segment of the logical record. |
| 1 | This is not the first segment of the logical record. | |||
| 3 | 1:6 | Successor | 0 | This is the last segment of the logical record. |
| 1 | This is not the last segment of the logical record. | |||
| 4 | 1:5 | Encryption | 0 | The segment is not encrypted. |
| 1 | The segment is encrypted. | |||
| 5 | 1:4 | Reserved | 0 | This bit is reserved for future use. |
| 6 | 1:3 | Checksum | 0 | The segment trailer does not have a checksum. |
| 1 | The segment trailer has a checksum. | |||
| 7 | 1:2 | Trailing length | 0 | The segment trailer does not have a trailing length. |
| 1 | The segment trailer has a trailing length. | |||
| 8 | 1:1 | Padding | 0 | The segment trailer does not have pad bytes. |
| 1 | The segment trailer has pad bytes. | |||
| 9 | 2:8-1 | Reserved | 0 | These bits are reserved for future use. |
1 All segments of a logical record must have the same value for the logical record structure bit.
2 When the predecessor bit is set, then the segment has a predecessor segment in the same logical record.
3 When the successor bit is set, then the segment has a successor segment in the same logical record.
4 All segments of a logical record must have the same value for the encryption bit. For rules on how to apply encryption, see 7.8.
5 This bit was previously used (in version 1) to indicate presence of the encryption packet. In the current version, presence of the encryption packet is determined by the predecessor and encryption bits.
6 See Table 5 and 7.6.
7 See Table 5.
8 See Table 5.
9 Bits 2:1-8 must be clear. Meanings for these bits may be defined in later editions of this part.
Table 4 describes the contents of an encryption packet.
| Table 4 - Logical Record Segment Encryption Packet Fields | |||
| *Note | Field | Size in Bytes | Representation Code |
| 1 | Packet length | 2 | UNORM |
| 2 | Producer code | 4 | ULONG |
| 3 | Translation tag | V | OBNAME |
| 4 | Encryption information | V | (see note) |
1 This is the length of the packet in bytes, including all fields. This field is required.
2 This is the organization code of the group responsible for the computer program that encrypted the record (see Appendix A). This field is required.
3 The translation tag is the name of an ORIGIN-TRANSLATION object. This field is required.
4 The encryption information is provided by the producer and has a representation known only to the producer (identified by the producer code field) of the logical record. It is used to assist producer-written computer programs in decrypting the logical record. It may consist of zero or more bytes.
The format of the encryption information is known only to the producer of the encrypted data. To the general reader, the encryption information field is just a group of bytes.(The following discussion uses terminology from Part 6). The purpose of the translation tag is to make it possible for "pass-through" copy-merge operations by organizations that encounter encrypted records they can't decrypt.
When data from two logical files is merged into a new logical file, some origin number collisions may occur (e.g., origin 3 is used in both input files). Such collisions are resolved by renaming the origin from one of the input files and all references to it in the output file. (This is called "origin translation"). Since origins in encrypted records can't be seen, they also cannot be translated. The translation tag in the encryption packet links this record with an optional ORIGIN-TRANSLATION object that has been recorded "in the clear" and that includes all the origins used in the encrypted record. When files are merged, the origins in the ORIGIN-TRANSLATION object, if provided, and the translation tag can be translated when copied. This makes it possible for later readers able to decrypt the merged data to figure out how to translate the origins in the decrypted record.
A zero-length segment body may be useful in the following situation:A logical record is "edited" by replacing it with a revised version. If the replacement has less data than the original, then the replacement will require less space than the original. However, a replacement must cover the original space exactly. One way to handle this is to add padding. However, if multiple segments are required (e.g., the logical record spans visible records), then the replacement body data may be used up before writing the last segment. In this case, the last segment may have a zero-length segment body.
Table 5 describes the contents of the logical record segment trailer.
| Table 5 - Logical Record Segment Trailer Fields | |||
| *Note | Field | Size in Bytes | Representation Code |
| 1 | Pad bytes | V | USHORT |
| 1 | Pad count | 4 | ULONG |
| 2 | Checksum | 2 | UNORM |
| 3 | Trailing length | 4 | ULONG |
1 The pad count value is 4 (its own size) plus the number of pad bytes when padding is present (padding bit set in the segment attributes). There may be zero or more pad bytes in addition to the pad count. The pad count is present if and only if the padding bit is set in the segment attributes. Padding is used to ensure an even length for a segment and also to extend a segment when necessary to fill out a fixed-length visible record, and may be used for other reasons.
2 The checksum is a two-byte value computed according to the algorithm given in 7.6. It is present if and only if the checksum bit is set in the segment attributes. The computation applies to everything in the segment that precedes the checksum and does not include itself or the trailing length. If the segment is encrypted, the checksum is computed after encryption has been applied.
3 The trailing length is present if and only if the trailing length bit is set in the segment attributes. When present, it is a copy of the length field from the segment header. Trailing lengths must be used consistently for all segments in a logical file (see 10.2). That is, all segments in a logical file must have a trailing length, or all segments must have no trailing length.
The length of the trailer is T + C + P, where T is 4 if the trailing length is present and zero otherwise, C is 2 if the checksum is present and zero otherwise, and P is the value in the pad count if padding is present and zero otherwise.When random access is supported by the device, and trailing lengths are present, it is possible for an implementation to read logical records from back to front.
1) c=0 initialize 16-bit checksum to zero
2) loop i=1,n,2 loop over the data two bytes at a time
3) t=byte(i+1)*256+byte(i) compute a 16-bit addend by concatenating
the next two bytes of data
4) c=c+t add the addend to the checksum
5) if carry c=c+1 add carry to checksum
6) c=c*2 left shift checksum
7) if carry c=c+1 add carry to checksum
8) endloop
When a logical record is encrypted, the encryption bit must be set in all segments.
The first segment must have an encryption packet, and no other segments may have an
encryption packet. Information required to decrypt the data (including use of any
extraneous bytes to satisfy encryption blocking requirements) is placed in the encryption
information field of the encryption packet.
Since encryption is applied without regard to segmentation, implementations
may need to support encryption and decryption methods that require inmemory buffering of entire logical record bodies. Unencrypted records, on the
other hand, can normally be accessed a segment at a time, and some
implementations may wish to utilize this feature to conserve memory when
processing very large logical records.
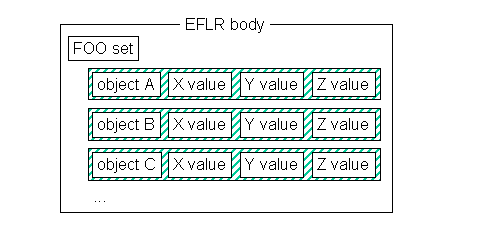 Figure 5 - Application-level view of a set (type = FOO)
Figure 5 - Application-level view of a set (type = FOO)
RP 66 uses the terms set, template, object, and attribute instead of table, heading, row, and column entry to emphasize the object-oriented features of the data items in an EFLR. Although the structure is "similar in nature to a table", there are enough differences from classical tables to warrant the newer terminology.
Implementation of the component parts of a set is done using a construct called
component. A component contains a descriptor that specifies which kind of data item the
component represents and contains subitems called characteristics that describe and
contain the value of the data item. A set, then, consists of a sequence of components.
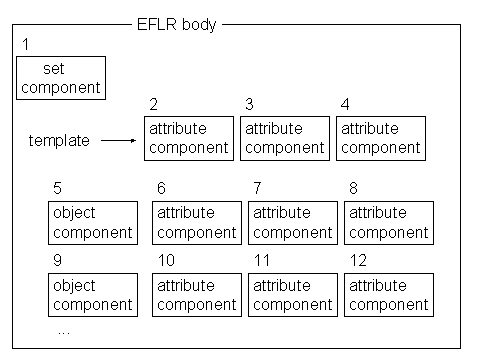 Figure 6 - Component-level view of a set
Figure 6 - Component-level view of a set
The detailed description of set structure is given in 8.3.
A component has a descriptor and zero or more characteristics. Table 6 describes the structure of a component. Bits are labeled 1 through 8, where 1 is the low-order bit.
| Table 6 - Component Structure | ||
| *Note | Field | Size in Bytes |
| 1 | Descriptor | 1 |
| 2 | Characteristics | V |
1 The descriptor of a component is subdivided into two disjoint bit fields. The first field, bits 8 - 6, represents the component's role (see Table 7). The second field, bits 5 - 1, represents the component's format (see 8.2.3).
2 A component has zero or more characteristics, as specified by the format subfield of the descriptor. The characteristics of a component identify, describe, and evaluate the data item represented by the component.
The component's role indicates what kind of data item the component represents and also determines which characteristics are represented by the format bits. Currently-defined component roles are described in Table 7.
| Table 7 - Component Role | |||
| *Note | Bits 8 - 6 | Symbolic Name | Type of Component |
| 1 | 000 | ABSATR | absent attribute |
| 2 | 001 | ATTRIB | attribute |
| 3 | 010 | ||
| 4 | 011 | OBJECT | object |
| 5 | 100 | ||
| 6 | 101 | RDSET | redundant set |
| 7 | 110 | RSET | replacement set |
| 8 | 111 | SET | normal set |
1 See 8.6.
2 See 8.6.
3 This role is reserved and currently has no meaning. In RP 66 version 1, this role represents an invariant attribute component. This component type is dropped in the current RP 66 version, since its use increases the complexity of implementations for very little benefit (at best one byte of storage savings per object when used).
4 See 8.5.
5 This role is reserved and currently has no meaning.
6 See 8.3.
7 See 8.3.
8 See 8.3.
The component's format specifies which of the characteristics for the given type
of component are actually present in the component. Each component type (identified by
its role) has a predefined group of characteristics that may occur in a predefined order.
Each characteristic is represented by a bit in the format field of the descriptor. The
characteristic is present in the component if and only if its bit is set. A global default value
may be specified as part of the definition of a characteristic. This is a value that shall be
assumed if the characteristic is not present. Characteristics immediately follow the
descriptor in the same order as the format bits by which they are specified. There are no
gaps for omitted characteristics.
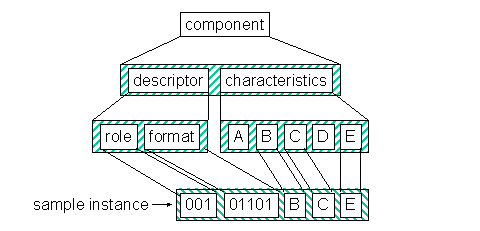 Figure 7 - Component structure
Figure 7 - Component structure
Any number of sets in a logical file may have the same object type, but no two may have the same non-null set name.
There are three kinds of set (see Table 7):
A normal set is as described in 8.3.1. It is the predominant kind of set.
A redundant set is an exact copy of a normal set written previously in the same logical file. Its purpose is to provide redundancy of information as insurance against possible data corruption (e.g., from media errors) of the normal set. The link between a redundant set and the normal set of which it is a copy is by means of the set name or type. If there is a redundant set, then it and the normal set of which it is a copy must have the same non-null set name unless the normal set is the only one in the logical file having a given type. In the latter case, set name is optional. Any number of redundant sets may be written for a given normal set.
There is a mechanism using UPDATE objects (see Part 6) for modifying the value
of an attribute previously written in a logical file. A replacement set is a near copy of a
normal set previously written in the same logical file, the difference being that the
replacement set reflects application of all updates that have been made between the time
the normal set was recorded and the time the replacement set is recorded. The replacement
set has the same objects as the normal set and the same attributes, but some attributes may
have updated values. The link between a replacement set and its corresponding normal set
is by means of the set name or type as described for redundant sets in 8.3.5. Any number
of replacement sets may be written for a given normal set.
Note that replacement sets are needed in lieu of redundant sets only when
updates have been applied to data in the normal set.
The purpose of replacement sets is to provide data replication when a logical
file spans multiple storage units. If a normal set is used to interpret the format
of an IFLR sequence (or affects computations using IFLR data), then having a
replacement set on each of multiple storage units ensures that loss of the initial
storage unit will not prevent the ability to read data on continuation storage
units.
A set's type, name, and object count are characteristics of a normal, redundant, or replacement set component. A normal, redundant, or replacement set component is the first component in the set, i.e., in the EFLR body. A set has exactly one normal, redundant, or replacement set component. Table 8 describes the format and characteristics of such components.
| Table 8 - Normal, Redundant, and Replacement Set Components | |||||
| *Note | Format Bit | Symbol | Characteristic | Representation Code | Global Default Value |
| 1 | 5 | t | type | TIDENT | (see note) |
| 2 | 4 | n | name | IDENT | null |
| 3 | 3 | c | count | ULONG | null |
| 4 | 2 - 1 | - | - | - | - |
1 The type characteristic identifies the object type of the objects in the set and references the schema (see Part 1) under which the object type (i.e., its list of available attributes and their meanings) is defined. The schema is obtained from the ORIGIN:SCHEMA-CODE attribute (see Part 6) located using the tag subfield (see Table 13) of the characteristic. The object type is given by the identifier subfield of the characteristic. A non-null value (both subfields) of this characteristic must always be explicitly present. There is no global default value.
2 When present the name must be non-null. It is optional unless required to establish a link between redundant and normal sets (see 8.3.5) or between replacement and normal sets (see 8.3.6). No two normal sets in a logical file may have the same non-null name.
3 The count characteristic is optional. When present and non-null it specifies the number of objects in the set. A null value is valid and indicates a count has not been provided.
4 These bits are reserved. For the current format version, they are always clear (value = 0).
The templates in two different sets having the same object type need not be the
same. They may differ by the order in which attribute components are written and also
may differ in the number and selection of attributes represented. The prototype object
written in a template represents a view (or subset) of the attributes defined by a schema for
a given object type. See Part 1 for a description of the methods used for defining a schema.
Whereas the object type is a name for the collection of attributes (i.e., column
headings) that may apply to the objects of the set, the template contains the list
of attributes actually used in the set, which may be a subset of the available
attributes.
A template is terminated when the first object component is encountered. There must be at least one object component in any set.
A schema may declare for each object type whether the identifier subfield of the object name is administered in a dictionary. If so, the ORIGIN:NAMESPACE-CODE and ORIGIN:NAMESPACE-NAME attributes identify the dictionary in which the identifier is included. The namespace assigns a permanent meaning to the identifier. When an object type has a dictionary-controlled identifier, the two-character prefix `U-' may be used to indicate an identifier not in the dictionary, in effect overriding the dictionary control on an instance by instance basis. No dictionary-administered object identifier may begin with these characters.
An object is written as one object component immediately followed by zero or
more attribute and/or absent attribute components. The attributes of an object correspond
in order to the attributes in the template, and any characteristic omitted from an attribute
component assumes the value of the corresponding characteristic from the template, or
global default value if also omitted from the template. Any characteristic explicitly present
in an object's attribute component overrides what is in the template. An object may not
have more attributes than the template.
Although an object may be followed by zero attribute components,
it still has one or more attributes due to
inheritance from the template, which must have at least one attribute.
It is invalid for an object to have all absent attributes,
since this would violate 8.5.1.
Use of an absent attribute component indicates that the attribute in that position has been deleted from the object, i.e., does not even have a default value.
An object may have fewer attribute components than its template. In this case, the
attributes for which components have been omitted assume all of the template default
characteristics for the object. Since attribute order in the object must match attribute order
in the template, only trailing components may be omitted, i.e., if a component is omitted
for any attribute, then components must also be omitted for all subsequent attributes for
the current object.
Note the difference between an omitted attribute component and an absent
attribute component. In the first case, the attribute exists and has value for the
object, whereas in the second case, the attribute has no existence and no
value for the object.
To use all template defaults, an "interior" attribute could have a component with
only a descriptor, i.e., with no explicit characteristics.
An object is terminated when the end of the logical record is reached or when another object component is encountered, whichever occurs first.
Table 9 describes the characteristics of an object component.
| Table 9 - Object Component | |||||
| *Note | Format Bit | Symbol | Characteristic | Representation Code | Global Default Value |
| 1 | 5 | n | name | OBNAME | (see note) |
| 2 | 4 - 1 | - | - | - | - |
1 The name characteristic uniquely identifies the object in a logical file and must be present. There is no global default value. To be unique in the logical file, the object name cannot match all three subfields - origin, copy number, identifier (see Table 13) - of any other object name in the logical file. The identifier subfield must be non-null.
2 These bits are reserved. For the current format version, they are always clear (value = 0).
An absent attribute has no characteristics and is represented by an absent attribute component, which has all format bits clear. The purpose of an absent attribute component is to occupy a position for an attribute that is declared in the template but is logically omitted from its object. An absent attribute component may only appear in an object and must not appear in a template. When it appears in an object, it indicates that the attribute corresponding to its position (as declared in the template) is omitted from the object and has no value, no count, no unit, and no representation code.
Table 10 describes the characteristics of an attribute component.
| Table 10 - Attribute Components | |||||
| *Note | Format Bit | Symbol | Characteristic | Representation Code | Global Default Value |
| 1 | 5 | l | label | IDENT | (see note) |
| 2 | 4 | c | count | UVARI | 1 |
| 2 | 3 | r | representation code | USHORT | IDENT |
| 2 | 2 | u | unit | UNITS | null |
| 3 | 1 | v | value | (see note) | null |
1 The label identifies an attribute. It is present if and only if the component is in the template. When present, the label must be non-null, and no two labels in the same template may be the same. There is no global default for the label.
2 The count, representation code, and unit describe the value. See note 3 for further detail.
3 The value characteristic represents the value of the attribute. A value consists of zero or more ordered elements, where the number of elements is given by count. Every element has the same representation code and same unit, specified by representation code and unit. Inheritance and consistency rules for attribute characteristics are given in 8.6.4.
The primary consistency rule for attribute characteristics is that count and
representation code must accurately describe the number and type of elements in value so
that the component can be parsed correctly. When a characteristic is present in an attribute
(its format bit is set), it has precedence over the corresponding characteristic in the
template (or global default if the attribute is in the template). Consistency among
characteristics is checked after inheritance, that is after template or global defaults are
obtained for omitted characteristics. After inheritance, if count = 0, value must have zero
elements. Count = 0 admits to two logical interpretations: If value is present, it is
considered to be a present but empty list. If value is omitted, it is considered to be absent.
After inheritance, if count > 0 value must have count elements. An inherited global default
value is considered to match any count. An inherited template value must match the actual
count after inheritance.
For example, if count = 3 and a global default value is inherited, then the
attribute is considered to have 3 global default elements. However, it is
inconsistent if 2 elements are inherited from the template when the attribute
count is 3.
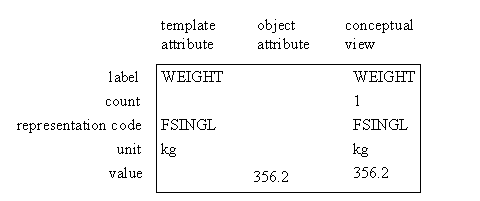

In this example it would be invalid to omit value from the object attribute, since this would lead to inconsistencies betwen the template value and the object attribute's count, representation code, and units.
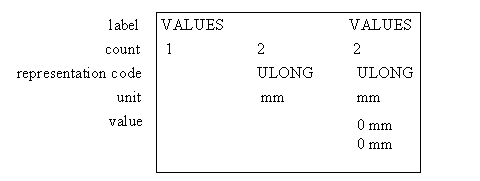
In this example the template value would be interpreted as one untiless blank string (null IDENT), whereas the object attribute's value consists of 2 null ULONG elements having unit 'mm'. There is no inconsistency with this template, since the template defers to the global default for value.Figure 8 - Examples of attribute components
The logical record body of an IFLR is divided into three parts. The first part is a
data descriptor reference (DDR) having representation code OBNAME. The second part
is a modifier having representation code USHORT. The third part is a sequence of 8-bit
bytes representing indirectly formatted data.
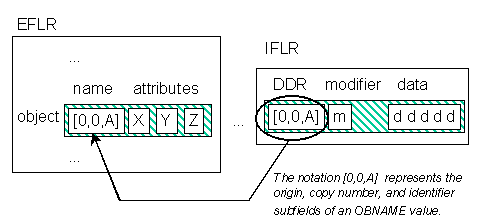 Figure 9 - Structure of an IFLR body and relation to its data descriptor
Figure 9 - Structure of an IFLR body and relation to its data descriptor
IFLRs are typically used to represent fixed-format records, where a potentially
large number of records need to be written efficiently both in time and space.
The data descriptor provides a one-time description of the fields in the record,
including necessary index fields, and the DDR provides the key needed to sort
out which format description goes with which record.
Any number of IFLRs in a logical file may have the same DDR. The sequence of
all IFLRs in a logical file having the same DDR is called an IFLR type. There may be any
number of IFLR types in a logical file, and there is no restriction on the order in which
individual records are written. IFLRs and EFLRs may be interspersed, and records from
one IFLR type may be interspersed with records of another IFLR type. The length of an
unmodified IFLR depends only on the rules expressed by its data descriptor, and different
records in the same IFLR type need not have the same length unless so constrained by the
data descriptor.
Being writable in any order means there are no restrictions about writing
EFLRs between IFLRs and vice-versa or about mixing IFLRs from different
IFLR types. However, the relative sequence of records in an IFLR type typically
is important and may be reflected by the required behavior of various index
fields. Some descriptors may define an implicit index based on position. For
example, the records of an IFLR type may represent data values on a grid.
Which point of the grid is evaluated for a given record might be computed as a
function of the record's sequential position in the IFLR type.
The modifier of an IFLR may be used to modify its use as described in Table 11.
| Table 11 - IFLR Modifier Options | |
| Value | Description |
| 0 | The IFLR is unmodified and is used as described in 9.2. |
| 1 | The IFLR is used as an end of data marker for an IFLR type. An end of data marker has only a DDR and modifier and no data. An end of data marker indicates the end of an IFLR type. That is, no unmodified IFLRs shall follow an end of data marker having the same DDR. Using an end of data marker is optional for an IFLR type. When used, any number of them may be written. |
| 2 - 255 | Reserved. |
The predecessor of end of data marker in RP66 V1 is the type 127 EOD record. The purpose of an end of data marker is to inform the reader when no more IFLRs of a given type will be seen. This allows the reader to stop looking for the "next" such IFLR, which may be very costly if a large amount of other data remains in the logical file.If the reader employs random access methods to skip over records when seeking an IFLR having a specified value or index, there is a chance its end of data marker may also be skipped. By writing end of data markers redundantly every so often, if one is missed another may be found before the reader has gone very far.
A logical file is a sequence of logical records that represent a coherent dataset.
Its purpose is to support the recording of a wide variety of kinds of data and to provide a
context within which its data can be identified. Because it is composed of logical records,
a logical file may be very small or arbitrarily large, and is not limited by its storage
medium. It is possible to pack many logical files sequentially onto a single physical
storage unit (see Part 3) or to span a logical file across two or more storage units.
Although putting the word "logical" in front of "file" all the time may seem
awkward, the distinction is important.
See Figure 1 for how logical files are related to logical and visible records.
Care is taken in this document to distinguish the term "logical file" from the
term "file". The latter typically refers to a physical file on disk and sometimes to
the data on a tape delimited by two tape marks. On traditional magnetic tapes
logical files are typically also physical files, although there will be at least one
physical file, namely the storage unit label, that is not a logical file. A disk file,
on the other hand, may contain one or more logical files and will always have a
storage unit label. Users may choose how to organize data, and on disk the
choice may be to have one logical file per disk file.
The complete description of logical files and the rules that govern them is
distributed among Parts 1, 2, 3, and 6 of this document. This part provides information
only on how logical files are related to the logical format layer of RP 66.
Most of the rules about a logical file concern its content, which is described in
detail in Part 6. The rules discussed here pertaining to the logical format layer
are relatively minimal.
The beginning of a logical file is determined from the content of its first logical record, which must be an EFLR. The specific object type of the set it contains is described in Part 6. Otherwise, a logical file consists of a sequence of arbitrarily many logical records until another logical file is encountered or until the sequence of logical records is exhausted.
Every logical record segment in a visible record must belong to the same logical
file. It follows that the first logical record of a logical file begins a new visible record.
There are several reasons for this rule. One is that the inclusion of file
sequence and file section numbers in the visible record header requires that all
segments belong to the same logical file. Another is that it makes it possible to
locate the beginning of a logical file efficiently, since only the first segment in
each visible record needs to be examined. A third reason is the compatibility
with traditional tape formats that is achieved
by mapping visible records one-to-one onto tape blocks
and then using tape marks to indicate blocks at which
logical files begin.
| Table 12 - Representation Code Summary | |||||
| Code | Symbolic Name | Description | Class | Type | Size in Bytes |
| 1 | FSHORT | Low precision floating point | NUMBER | S | 2 |
| 2 | FSINGL | IEEE single precision floating point | NUMBER | S | 4 |
| 3 | FSING1 | Validated single precision floating point | BALANCED-INTERVAL | C | 8 |
| 4 | FSING2 | Two-way validated single precision floating point | UNBALANCED-INTERVAL | C | 12 |
| 5 | ISINGL | IBM single precision floating point | NUMBER | S | 4 |
| 6 | VSINGL | VAX single precision floating point | NUMBER | S | 4 |
| 7 | FDOUBL | IEEE double precision floating point | NUMBER | S | 8 |
| 8 | FDOUB1 | Validated double precision floating point | BALANCED-INTERVAL | C | 16 |
| 9 | FDOUB2 | Two-way validated double precision floating point | UNBALANCED-INTERVAL | C | 24 |
| 10 | CSINGL | Single precision complex | COMPLEX | C | 8 |
| 11 | CDOUBL | Double precision complex | COMPLEX | C | 16 |
| 12 | SSHORT | Short signed integer | NUMBER | S | 1 |
| 13 | SNORM | Normal signed integer | NUMBER | S | 2 |
| 14 | SLONG | Long signed integer | NUMBER | S | 4 |
| 15 | USHORT | Short unsigned integer | NUMBER | S | 1 |
| 16 | UNORM | Normal unsigned integer | NUMBER | S | 2 |
| 17 | ULONG | Long unsigned integer | NUMBER | S | 4 |
| 18 | UVARI | Variable-length unsigned integer | NUMBER | S | 1, 2, or 4 |
| 19 | IDENT | Variable-length identifier | STRING | S | V |
| 20 | ASCII | Variable-length ASCII character string | STRING | S | V |
| 21 | DTIME | Date and time | TIME | C | 8 |
| 22 | ORIGIN | Origin reference | ORIGIN | S | V |
| 23 | OBNAME | Object name | REFERENCE | C | V |
| 24 | OBJREF | Object reference | REFERENCE | C | V |
| 25 | ATTREF | Attribute reference | ATTRIBUTE | C | V |
| 26 | STATUS | Boolean status | STATUS | S | 1 |
| 27 | UNITS | Units expression | UNIT | S | V |
| 28 | RNORM | Rational | RATIO | C erroneously marked 'S' in prior publication | 4 |
| 29 | RLONG | Long rational | RATIO | C erroneously marked 'S' in prior publication | 8 |
| 30 | ISNORM | Inverted order normal signed integer | NUMBER | S | 2 |
| 31 | ISLONG | Inverted order long signed integer | NUMBER | S | 4 |
| 32 | IUNORM | Inverted order normal unsigned integer | NUMBER | S | 2 |
| 33 | IULONG | Inverted order long unsigned integer | NUMBER | S | 4 |
| 34 | IRNORM | Inverted order rational | RATIO | C erroneously marked 'S' in prior publication | 4 |
| 35 | IRLONG | Inverted order long rational | RATIO | C erroneously marked 'S' in prior publication | 8 |
| 36 | TIDENT | Tagged IDENT | TAG-STRING | C | V |
| 37 | TUNORM | Tagged UNORM | TAG-NUMBER | C | 3, 4, or 6 |
| 38 | TASCII | Tagged ASCII | TAG-STRING | C | V |
| 39 | LOGICL | Logical | STATUS | S | 1 |
| 40 | BINARY | Binary | BINARY | S | V |
| 41 | FRATIO | Floating point ratio | RATIO | C | 8 |
| 42 | DRATIO | Double precision ratio | RATIO | C | 16 |
The bit-labeling convention here is the opposite of the convention used in RP 66 V1. The change was made in order to match the conventions used by cited standards.
| Byte | Field
| 1 to k
| N (UVARI)
| (k+1) to (k+N)
| 7-bit ASCII or ISO 8859-1 characters
| |
Note that ASCII and ISO 8859-1 characters are the same where both sets overlap. This is typically called the G0 graphic character set. ASCII includes control characters that are not part of 8859-1, and 8859-1 includes a G1 graphic character set using bit 8 that is not part of ASCII.The use of a null character as a string delimiter allows transparent string padding, i.e., writing more characters than are in the actual string data. This makes it possible to write variable-length string data in fixed-length fields (e.g., in frames) while preserving the extent of the actual string value.
#bits = 8 * (N - 1) - P, when N > 1.
Since P < 8, a bit string is written in the minimum number of bytes.
| Byte | Field
| 1 to k
| N (UVARI)
| k + 1
| P (USHORT)
| (k+2) to (k+N)
| Bit string, left justified
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| -1
| S
| 7
| 210
| E
| 6
| 29
| 5
| 28
| 4
| 27
| 3
| 26
| 2
| 25
| 1
| 24
| 2
| 8
| 23
| 7
| 22
| 6
| 21
| 5
| 20
| 4
| 2-1
| M
| 3
| 2-2
| 2
| 2-3
| 1
| 2-4
| 3
| 8
| 2-5
| 7
| 2-6
| 6
| 2-7
| 5
| 2-8
| 4
| 2-9
| 3
| 2-10
| 2
| 2-11
| 1
| 2-12
| 4
| 8
| 2-13
| 7
| 2-14
| 6
| 2-15
| 5
| 2-16
| 4
| 2-17
| 3
| 2-18
| 2
| 2-19
| 1
| 2-20
| 5
| 8
| 2-21
| 7
| 2-22
| 6
| 2-23
| 5
| 2-24
| 4
| 2-25
| 3
| 2-26
| 2
| 2-27
| 1
| 2-28
| 6
| 8
| 2-29
| 7
| 2-30
| 6
| 2-31
| 5
| 2-32
| 4
| 2-33
| 3
| 2-34
| 2
| 2-35
| 1
| 2-36
| 7
| 8
| 2-37
| 7
| 2-38
| 6
| 2-39
| 5
| 2-40
| 4
| 2-41
| 3
| 2-42
| 2
| 2-43
| 1
| 2-44
| 8
| 8
| 2-45
| 7
| 2-46
| 6
| 2-47
| 5
| 2-48
| 4
| 2-49
| 3
| 2-50
| 2
| 2-51
| 1
| 2-52
| |
Note: Netscape Communicator 4.7: entity∞ (∞ - infinity sign) displays as ?
| Byte | Bit | Meaning | Field
| 1
| 8
| -1
| M
| 7
| 2-1
| 6
| 2-2
| 5
| 2-3
| 4
| 2-4
| 3
| 2-5
| 2
| 2-6
| 1
| 2-7
| 2
| 8
| 2-8
| 7
| 2-9
| 6
| 2-10
| 5
| 2-11
| 4
| 23
| E
| 3
| 22
| 2
| 21
| 1
| 20
| |
two's complement of negative number is one's complement plus one; one's complement is two's complement of positive value with each bit reversed= 10110011 01112 one's complement + 00000000 00012 one + 10002 exponent = 10110011 100010002
| Byte | Bit | Meaning | Field
| 1
| 8
| -1
| S
| 7
| 27
| E
| 6
| 26
| 5
| 25
| 4
| 24
| 3
| 23
| 2
| 22
| 1
| 21
| 2
| 8
| 20
| 7
| 2-1
| M
| 6
| 2-2
| 5
| 2-3
| 4
| 2-4
| 3
| 2-5
| 2
| 2-6
| 1
| 2-7
| 3
| 8
| 2-8
| 7
| 2-9
| 6
| 2-10
| 5
| 2-11
| 4
| 2-12
| 3
| 2-13
| 2
| 2-14
| 1
| 2-15
| 4
| 8
| 2-16
| 7
| 2-17
| 6
| 2-18
| 5
| 2-19
| 4
| 2-20
| 3
| 2-21
| 2
| 2-22
| 1
| 2-23
| |
Note: Netscape Communicator 4.7: entity∞ (∞ - infinity sign) displays as ?
The purpose for IDENT is primarily for labels and other identifiers that undergo matching. Restriction to upper case allows implementations to avoid case conversion prior to matching. Exclusion of white space helps prevent visual ambiguity.The use of a null character as a string delimiter allows transparent string padding, i.e., writing more characters than are in the actual string data. This makes it possible to write variable-length string data in fixed-length fields (e.g., in frames) while preserving the extent of the actual string value.
| Byte | Field
| 1
| N (USHORT)
| 2 to (1 + N)
| 7-bit ASCII characters
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| -1
| S
| 7
| 26
| E
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| 2
| 8
| 2-1
| M
| 7
| 2-2
| 6
| 2-3
| 5
| 2-4
| 4
| 2-5
| 3
| 2-6
| 2
| 2-7
| 1
| 2-8
| 3
| 8
| 2-9
| 7
| 2-10
| 6
| 2-11
| 5
| 2-12
| 4
| 2-13
| 3
| 2-14
| 2
| 2-15
| 1
| 2-16
| 4
| 8
| 2-17
| 7
| 2-18
| 6
| 2-19
| 5
| 2-20
| 4
| 2-21
| 3
| 2-22
| 2
| 2-23
| 1
| 2-24
| |
| Byte | Bit | Meaning | Field
| 4
| 8
| -231
| I
| 7
| 230
| 6
| 229
| 5
| 228
| 4
| 227
| 3
| 226
| 2
| 225
| 1
| 224
| 3
| 8
| 223
| 7
| 222
| 6
| 221
| 5
| 220
| 4
| 219
| 3
| 218
| 2
| 217
| 1
| 216
| 2
| 8
| 215
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 1
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | Bit | Meaning | Field
| 2
| 8
| -215
| I
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 1
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | Bit | Meaning | Field
| 4
| 8
| 231
| I
| 7
| 230
| 6
| 229
| 5
| 228
| 4
| 227
| 3
| 226
| 2
| 225
| 1
| 224
| 3
| 8
| 223
| 7
| 222
| 6
| 221
| 5
| 220
| 4
| 219
| 3
| 218
| 2
| 217
| 1
| 216
| 2
| 8
| 215
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 1
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | Bit | Meaning | Field
| 2
| 8
| 215
| I
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 1
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | 1 |
| Field | S (SSHORT) |
The representation code acts as a tag to identify values that may need origin translation when data is merged (see Table 4).
| Byte | Field
| 1 - k
| O (UVARI)
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| -231
| I
| 7
| 230
| 6
| 229
| 5
| 228
| 4
| 227
| 3
| 226
| 2
| 225
| 1
| 224
| 2
| 8
| 223
| 7
| 222
| 6
| 221
| 5
| 220
| 4
| 219
| 3
| 218
| 2
| 217
| 1
| 216
| 3
| 8
| 215
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 4
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
two's complement of negative number is one's complement plus one; one's complement is two's complement of positive value with each bit reversed= 11111111 11111111 11111111 011001102 + 1 = 11111111 11111111 11111111 011001112
| Byte | Bit | Meaning | Field
| 1
| 8
| -215
| I
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 2
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
two's complement of negative number is one's complement plus one; one's complement is two's complement of positive value with each bit reversed= 11111111 011001102 + 1 = 11111111 011001112
| Byte | Bit | Meaning | Field
| 1
| 8
| -27
| I
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
two's complement of negative number is one's complement plus one; one's complement is two's complement of positive value with each bit reversed= 101001102 + 1 = 101001112
| Byte | Field
| 1
| S (SSHORT)
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| 231
| I
| 7
| 230
| 6
| 229
| 5
| 228
| 4
| 227
| 3
| 226
| 2
| 225
| 1
| 224
| 2
| 8
| 223
| 7
| 222
| 6
| 221
| 5
| 220
| 4
| 219
| 3
| 218
| 2
| 217
| 1
| 216
| 3
| 8
| 215
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 4
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| 215
| I
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 2
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| 27
| I
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
The tabular representation of the one-byte representation as originally published incorrectly excluded bit 7 from the bits representing the value.
| Byte | Bit | Meaning | Field
| 1
| 8
| 0
| -
| 7
| 26
| I
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| 1
| -
| 7
| 0
| 6
| 213
| I
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 2
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
| Byte | Bit | Meaning | Field
| 1
| 8
| 1
| -
| 7
| 1
| 6
| 229
| I
| 5
| 228
| 4
| 227
| 3
| 226
| 2
| 225
| 1
| 224
| 2
| 8
| 223
| 7
| 222
| 6
| 221
| 5
| 220
| 4
| 219
| 3
| 218
| 2
| 217
| 1
| 216
| 3
| 8
| 215
| 7
| 214
| 6
| 213
| 5
| 212
| 4
| 211
| 3
| 210
| 2
| 29
| 1
| 28
| 4
| 8
| 27
| 7
| 26
| 6
| 25
| 5
| 24
| 4
| 23
| 3
| 22
| 2
| 21
| 1
| 20
| |
Caution: Note the unusual byte ordering in this diagram.
| Byte | Bit | Meaning | Field
| 2
| 8
| -1
| S
| 7
| 27
| E
| 6
| 26
| 5
| 25
| 4
| 24
| 3
| 23
| 2
| 22
| 1
| 21
| 1
| 8
| 20
| 7
| 2-2
| M
| 6
| 2-3
| 5
| 2-4
| 4
| 2-5
| 3
| 2-6
| 2
| 2-7
| 1
| 2-8
| 4
| 8
| 2-9
| 7
| 2-10
| 6
| 2-11
| 5
| 2-12
| 4
| 2-13
| 3
| 2-14
| 2
| 2-15
| 1
| 2-16
| 3
| 8
| 2-17
| 7
| 2-18
| 6
| 2-19
| 5
| 2-20
| 4
| 2-21
| 3
| 2-22
| 2
| 2-23
| 1
| 2-24
| |
| Table 13 - Compound Representation Code Descriptions | ||||
| Symbolic Name | Subfield Position | Subfield Name | Subfield Code | Description |
| ATTREF | 1 | type | IDENT | Object type name. |
| 2 | origin | ORIGIN | Origin containing schema code and identifier namespace code. | |
| 3 | copy | UVARI | Copy number. | |
| 4 | identifier | IDENT | Object identifier. | |
| 5 | label | IDENT | Attribute label. | |
| CDOUBL | 1 | real | FDOUBL | Real part. |
| 2 | imaginary | FDOUBL | Imaginary part. | |
| CSINGL | 1 | real | FSINGL | Real part. |
| 2 | imaginary | FSINGL | Imaginary part. | |
| DRATIO | 1 | numerator | FDOUBL | Numerator of ratio. |
| 2 | denominator | FDOUBL | Denominator of ratio (> 0). | |
| DTIME | 1 | year | USHORT | Years since 1900. |
| 2 | timezone | 4-bit unsigned integer | Time zone: 0=local standard time, 1=local daylight savings time, 2 = Universal Coordinated Time (Greenwich Mean Time). | |
| 3 | month | 4-bit unsigned integer | Month of the year (1 to 12). | |
| 4 | day | USHORT | Day of the month (1 to 31). | |
| 5 | hour | USHORT | Hours since midnight (0 to 3). | |
| 6 | minute | USHORT | Minutes past the hour (0 to 59). | |
| 7 | second | USHORT | Seconds past the minute (0 to 59). | |
| 8 | millisecond | UNORM | Milliseconds past the second (0 to 999). | |
| FDOUB1 | 1 | value | FDOUBL | Nominal value V of interval [V - B, V + B]. |
| 2 | bound | FDOUBL | Interval bound, B (>= 0). | |
| FDOUB2 | 1 | value | FDOUBL | Nominal value V of interval [V - A, V + B]. |
| 2 | lower | FDOUBL | Interval lower bound, A (>= 0). | |
| 3 | upper | FDOUBL | Interval upper bound, B (>= 0). | |
| FRATIO | 1 | numerator | FSINGL | Numerator of ratio. |
| 2 | denominator | FSINGL | Denominator of ratio (> 0). | |
| FSING1 | 1 | value | FSINGL | Nominal value V of interval [V - B, V + B]. |
| 2 | bound | FSINGL | Interval bound, B (>= 0). | |
| FSING2 | 1 | value | FSINGL | Nominal value V of interval [V - A, V + B]. |
| 2 | lower | FSINGL | Interval lower bound, A (>= 0)). | |
| 3 | upper | FSINGL | Interval upper bound, B (>= 0). | |
| IRLONG | 1 | numerator | ISLONG | Numerator of ratio. |
| 2 | denominator | IULONG | Denominator of ratio (> 0). | |
| IRNORM | 1 | numerator | ISNORM | Numerator of ratio. |
| 2 | denominator | IUNORM | Denominator of ratio (> 0). | |
| OBJREF | 1 | type | IDENT | Object type name. |
| 2 | origin | ORIGIN | Origin containing schema code and identifier namespace code. | |
| 3 | copy | UVARI | Copy number. | |
| 4 | identifier | IDENT | Object identifier. | |
| OBNAME | 1 | origin | ORIGIN | Origin containing identifier namespace code. |
| 2 | copy | UVARI | Copy number. | |
| 3 | identifier | IDENT | Object identifier. | |
| RLONG | 1 | numerator | SLONG | Numerator of ratio. |
| 2 | denominator | ULONG | Denominator of ratio (> 0). | |
| RNORM | 1 | numerator | SNORM | Numerator of ratio. |
| 2 | denominator | UNORM | Denominator of ratio (> 0). | |
| TASCII | 1 | tag | ORIGIN | Origin reference. |
| 2 | string | ASCII | Character string value. | |
| TIDENT | 1 | tag | ORIGIN | Origin reference. |
| 2 | identifier | IDENT | Identifier. | |
| TUNORM | 1 | tag | ORIGIN | Origin reference. |
| 2 | value | UNORM | An unsigned integer value. | |
The copy number subfield, which was USHORT in RP 66 V1, is now UVARI.
Sample value:
midnight, January 1, 1900, local standard time
= 00000000 00000000 00000000 000000002
The copy number subfield, which was USHORT in RP 66 V1, is now UVARI.
The copy number subfield, which was USHORT in RP 66 V1, is now UVARI.
The following representation code descriptions (CSINGL, CDOUBL, RNORM, RLONG, FRATIO, DRATIO, IRNORM, IRLONG) were unintentionally omitted in prior publications of RP66 V2.